A scientific approach to teaching
20 Oct 2022 |

random trip report |
Introduction
I believe that:
- The human brain is capable of learning far more, and far faster, than is possible with current educational systems.
- If efficient learning is available to people, it will largely supplant passive activities like mass media and social media, and various social benefits will accrue.
Personally, I'd like to know about a lot of things: the geology and botany of the Sierra Nevada, the independence of the Continuum Hypothesis, etc. I know these topics at a superficial level, but I believe my brain has the capacity to know them all at a deep level. The educational vehicles available to me - adult school classes, online courses, YouTube videos - either don't work at all for me, or are so time-inefficient that I don't have time for them.
This essay proposes an approach to teaching intended to let people achieve their full learning potential. I call it Scientific Teaching (ST) because it's based on experimentation and inference from data rather than the intuition and biases of individuals. In that sense it's analogous to scientific government.
Note: by "teaching" I mean a) presenting information to a student, b) verifying that it's been absorbed, and c) ensuring that it eventually makes its way to the student's long-term memory. Things like Wikipedia, YouTube and Khan Academy, for example, do a) but not b) or c).
ST is computer- and Web-based. It presents lessons through digital devices (laptops, smartphones, VR interfaces). Lessons and other data are stored on central servers and delivered via the Internet. The only software needed on the client (student) side is a web browser.
ST can be used as a stand-alone system for teaching information. Of course, this is only part of education. Education includes higher-level aspects such as creativity, the complex synthesis of concepts, and hands-on activities, as well as social and communicational components. ST doesn't encompass these aspects, but it can be used as part of a larger system, such as an in-person school, that does.
The goals of ST include:
- Time-efficiency; i.e. to maximize learning per unit instruction time.
- Scalablitye: to be able teach millions or billions of students cost-effectively (i.e. the incremental cost per student is computer capacity, not human time).
- Effectiveness for a wide range of students, in terms of age and other demographics, learning abilities, goals, and usage level (full-time or sporadic).
The need for a better way to teach
Civilization has produced mountains of knowledge in all areas - science, literature, history, math, the arts, etc. One person can no longer come close to knowing everything. But I think it's good for people to know a lot about a lot of things because:
- Knowledge makes life more interesting and meaningful.
- Societies with more knowledgeable citizenry tend to be more just and fair, and their members tend to be happier. If there is a common basis of knowledge, society is less fragmented.
- Such societies make decisions that increase the likelihood of long-term human survival.
Most teaching - at all levels - is still done using the "classroom model", in which students take semester-long classes, attend 60-90 minute lectures, do homework, and take quizzes and tests. This model is inherently time-inefficient, for many reasons:
- Teaching does not reflect the variation in students: their preferred learning style, capacity, interests, and attention span.
- Learning is temporary; students may forget everything after the final exam.
- Many (or perhaps most) teachers are not very good. This is exacerbated by the fact that teachers are underpaid because of anti-tax, anti-government zealotry.
So knowledge has exploded but the rate of learning has not. As a result:
- An individual's education is increasingly narrow. Reaching the frontier in any area takes so much time that it precludes learning much about anything else. It takes an increasing number of years to reach a frontier.
- Education is increasingly superficial. In science, we're taught the currently accepted theories, but not how they were reached.
The classroom model is expensive: a YouTube video can reach millions of people over many years, but a lecture reaches only a few dozen people, once. This has social consequences:
- In countries like the U.S., rich communities have better schools than poor ones. Rich people can afford high-end colleges and poor people can't. So the education system perpetuates social inequality.
- In poor countries, few people can afford much education at all, perpetuating poverty and inequality at a global level.
Finally, education is typically packed into ages 5-21 or so, and then it ends abruptly. We teach people before they know why it's relevant. By the time the teaching is relevant, much of it has been forgotten.
ST is intended to address these problems by a) making it feasible to learn a lot about a lot of things, b) making this affordable (ideally, free), and c) spreading the learning process across an individual's entire life.
Overview of scientific teaching
ST is based on three central ideas. First: for each concept to be taught, ST has lots (dozens or hundreds) of "lessons" that teach it in different ways. To teach the concept to a given student, ST uses the lesson that's most likely to be effective for that student.
Currently, a concept in the mainstream curriculum is typically covered in scores of textbooks, scores of YouTube videos, and tens of thousands of lectures (a few of them recorded). These "lessons" may differ in learning mode, medium, language level, assumptions about student interests, and so on. Some are terrible, some are great; some are great but only for a (possibly small) subset of students. But a student only sees one of them, and almost certainly not the optimal one.
Second: ST doesn'tt just teach a concept once; it refreshes it at intervals (months and years) in a way that efficiently moves it to the student's long-term memory.
Third: ST's teaching decisions (which lessons to show a student, when to refresh concepts) are based on empirical data rather than a priori assumptions. It records every student interaction in detail, in a central database: the number of seconds the student viewed a lesson, the results of each assessment, and so on. It analyzes this data, using multiple methods (principal component analysis, machine learning, etc.) to learn about each student and each lesson, with the goal of teaching efficiently and permanently.
To implement these ideas, ST involves several components. Each is discussed in more detail later; here's a top-level view:
- The set of concepts, ideas and facts to be taught is structured as a hierarchical, fine-grained "concept graph". Concepts can be related in several ways: given two concepts A and B, A may be a prerequisite to B, included in B, or an example of B.
- ST has an evolving set of "lessons": units of material that teach and/or assess the comprehension of a particular concept. There may be many lessons for a given concept. These lessons may differ in various ways; medium (text, video, web pages, VR), learning mode, choice of examples, and so on.
- For each student, ST maintains a) demographic and other explicit info; b) a detailed history of the student's interactions with lessons; c) data derived from analyses of these interactions, modeling various aspects of the student's learning traits and abilities.
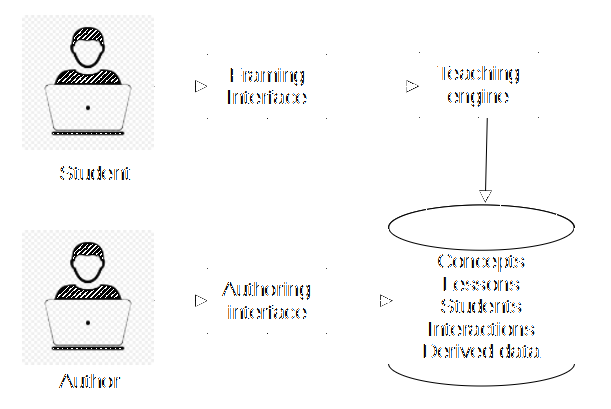
- Students interact with ST in "sessions" that involve viewing sequences of lessons and other activities. Lessons are enclosed in a web-based "framing interface". A "teaching engine" decides what to show and when, based on student data, lesson data, and other factors.
- "ST authors" are people who develop and refine lessons. ST gives them an array of tools and information helping them do this.
Concepts
A "concept" represents a unit of information to be taught. Concepts can be broad (number theory) or narrow (the definition of primality).
Note: "concept" is not an ideal term for this, but I can't think of a better one.
Two concepts A and B can be related in several ways:
- A generalizes B: i.e., if you know A, you also know B.
- A is a prerequisite of B: in order to know B, you must first know A (or some concept that generalizes A).
- A is an example of B: knowing A can reinforce your knowledge of B.
Ideas generally have many levels; for example, the Fourier transform can be understood in terms of real functions, or complex functions, or Hilbert spaces, or many other higher-level mathematical ideas. In ST, each of these levels would be represented by a different concept, connected by including and possibly prerequisite.
If {B1...Bn} generalizes A, we say that {B1...Bn} is a decomposition of A. A concept with no decompositions is called "atomic". Atomic concepts should be narrow enough that they can be explained in a single lesson of a few (<~10) minutes.
The idea of a concept graph is admittedly fraught with problems. Decomposing a complex set of ideas into a hierarchy of pieces implies a particular understanding of the ideas - an editorial bias. This may be a source of conflict among the community charged with developing the concept graph; a wikipedia-type approach may be needed. The very idea of a hierarchy of concepts can be accused of being reductionist, and indeed it is.
But ST needs something like this; something to hang lessons off of that lets us say that two lessons teach the same thing, or that one lesson assesses what another one teaches.
There is no notion of "course" in ST - no notion of a fixed sequence of concepts. An order may be determined by prerequisites: if we want to teach C, and there are concepts A -> B -> C (where -> denotes prerequisite), then we have to teach A, B, and C in that order. But if the prerequisites are A->C and B->C, then we can teach either A or B first. We might want to pick the one that the student already knows something about, or has an interest in.
Lessons
A lesson is a unit of content that a student can view and/or interact with. Each lesson is linked to a concept C. The lesson may teach the concept, assess comprehension of it, or both. Lessons serve as homework and tests. A lesson may have additional concept prerequisites (beyond those of C).
There may be many lessons connect to a given concept, and they may differ in various ways. For example, a lesson about the Fourier Transform may
- be textual, graphical, or animated;
- be motivated by a particular application (music, astronomy, geology etc.) and may therefore have additional prerequisites;
- be expressed in terms of real numbers, complex numbers, or something more abstract; that determines which specific concept it's linked to.
The "size" of a lesson (the average time needed for a student to view or perform it) is arbitrary. However, it generally should be small (a few minutes), because
- Long lessons may not be effective for students with short attention spans.
- ST tries to measure the effectiveness of lessons. If a lesson contains several pieces, of which some are effective and some are not, ST can't figure this out.
Lessons are immutable. Once a lesson has been added to ST, and a student has viewed it, it can't be changed; doing so might invalidate what ST has learned about the original lesson (even if the lesson developer doesn't think so). The developer can deprecate it (in which case ST won't use it further) or add a new lesson with a "based on" link to the old one, which tells ST that its derived data is probably similar to that of the old one.
Lessons may be in various formats:
- Text.
- Semantics-annotated text (see below).
- An HTML page.
- A Javascript program.
- For VR lessons, 3D info (VRML or similar).
- For interactive lessons, a specification of the interactive interface: an HTML form (checkboxes, radio buttons, text fields) or some richer format.
Ideally, ST should have many lessons for each atomic concept. The ST lesson database can potentially be seeded with Wikipedia articles, Khan Academy lessons, or YouTube videos. Eventually these would be replaced by ST-specific lessons.
Presenting text
Most teaching involves presenting text to the student. We should try to do this in a way that's maximally effective for that student.
A study showed that when students read text, the spacing between words, phrases, sentences, and paragraphs can significantly affect comprehension. If you adjust inter-word spacing to call attention to key words and phrases, readers understand more.
I'm sure that other typographical techniques, e.g. changing the size or color of particular words, or animating the text, also affect comprehension. These techniques are used in advertising. I'm sure that basic typography - the font, font size, line spacing, and color - affects comprehension too. And I'm sure that all these effects are student-dependent.
Text can also be presented aurally - as speech - either by playing a recording of a human speaker, or using text-to-speech. When text is presented as speech, there are many parameters that may affect comprehension: speed, accent, pitch, amount of inflection, and so on. We've all had teachers whose monotone delivery caused us to zone out and not listen or absorb. At the other extreme, a voice like that of Patrick Stewart makes me perk up and listen to every word.
As far as I know, no current educational channels, formal or informal, use any of these techniques. Here's how ST would use these techniques:
- The text in lessons could be "semantically annotated" to mark the important words and phrases; these would guide the typography and speech-inflection adjustments described above.
- For each student, ST would do experiments using "calibration lessons" (see below) to learn the most effective text representation (printed or spoken) and parameters. These could potenially vary depending on the student's mental state (i.e. graphical might be more effective when they're fresh, aural when they're tired).
Background music
I've noticed that many educational YouTube videos have background music - usually electronic techno-type music, at a low, almost subliminal volume level. It's possible that this music enhances comprehension. Perhaps it stimulates the student's nervous system a bit, or creates a subconscious feeling that the video is exciting and important.
If this is the case, background music should be a feature of ST. ST could - via experimentation using calibration lessons - learn what background music works best for each student; i.e. the type, volume, tempo, etc. This may vary with mental state and attention.
Background music should not be built into lessons. It should be added by ST, in a personalized fashion, based on the results of these experiments.
Calibration and stimulator lessons
"Calibration lessons" are short assessment lessons, not connected to a concept, intended to measure the student's current learning capacity. They might consist of a reading comprehension test or a memorization problem. They are used by ST for various purposes:
- To estimate a student's current mental state and to model their attention (see below),
- To study the student's individual response to typography and background music (see above).
ST may also have "stimulator lessons" (Lumosity-type games) that can be used to improve a student's mental state.
Students
ST keeps track of the various info about each student. Some of this is supplied by the student:
- Demographics: sex, age, nationality.
- Goals: the set of (high-level) concepts the student wants to know. A student can assign a "resource share" to each one; this specifies the fraction of time to spend on it.
- Interests (concepts or keywords).
- Their primary language.
- Their language level (e.g. vocabulary, complex-sentence comprehension).
- Memory state: what the student knows, and when it was last refreshed.
- Memory model (see below).
- Attention model (see below).
- Learning model: results of PCA or ML analysis of lesson effectiveness. This encompasses the student's preferred learning mode and other factors.
Mental state
At a given point, a student has a "mental state", which may depend on how they slept the previous night, their blood sugar level, whether they're upset or distracted, the time of day, and other factors. It can change rapidly.
Mental state affects learning. Depending on a student's mental state, it might be more time-effective to
- present new concepts
- review concepts
- not do any teaching at all; encourage the student to take a nap, get something to eat, or recreate.
There are presumably ways of quickly estimating a student's mental state. It's also likely that there are ways of modifying the mental state. This is the premise of Lumosity, which has you play games that ostensibly make you more alert.
Attention model
In addition to their mental state, a student's ability to absorb information may change (typically decline) during a teaching session. This is student-dependent. The decline may be gradual or abrupt, and the "attention span" may be hours or minutes.
A student's attention may decline below the level where teaching is effective. Depending on the student, restoring their attention may require
- taking a physical break (e.g. getting up and walking around)
- staying at the computer, but switching to a non-teaching activity
- continuing in ST, but switching to a different topic.
Classroom education typically assumes that attention span is one hour and the reset period is 10 minutes. These parameters may be way off for some students, e.g. those with ADD.
ST maintains an "attention model" for each student - an estimate of the duration and decay rate of their attention, and the parameters of an attention reset. This model is computed and refined empirically, based on calibration lessons.
Lesson effectiveness
Measuring effectiveness
When a student views a lesson, ST tries to measure their comprehension of it: the fraction (0..1) of the concept that they understand. Some lessons may include their own assessment. Otherwise the ST picks an assessment lesson and shows it either immediately or soon after the original lesson.
The "effectiveness" of a lesson view is a function of a) the student's comprehension of the concept after viewing the lesson, and b) the time the view took. Comprehension is the dominant factor, but a 1-minute lesson is better than a 10-minute lesson if it teaches the same thing.
Predicting effectiveness
Suppose we want to teach a concept C to a student S The ST system may have many lessons L that teach C. To decide which of these to show, we want to predict L's effectiveness for S at the current time.
This estimation can reflect the complete history of all interactions, in particular
- All of S's interactions with other lessons, and the measured comprehension of each.
- All other students' interactions with L, and the measured comprehensions.
There are many possible ways to do this. For example, borrowing ideas from social filtering, we might identify students who are similar to S and who viewed L, and take the average of their comprehensions of L. Or we could use principal component analysis to digest the interaction data; model each student S and each lesson L as a vector such that the dot product of S and L is a good predictor of S's comprehension of L. Or we could use demographic data - a particular lesson might be extremely effective for 14-18 year old males.
To be accurate, any prediction method requires data - probably lots of data, across a wide range of students. When a new lesson is added, or when an existing lesson is significantly modified, ST will need to show the lesson to students for which an accurate prediction is not possible.
Memory and refresh
The first time a student learns a concept, it goes into their short-term memory. They forget it in a day or two unless it's 'refreshed', either internally (by thinking about it or using it for some purpose) or externally (by being reminded of it). Each refresh moves the information deeper into memory. To move a concept into long-term (more or less permanent) memory, it needs to be refreshed some number of times, at some intervals. The optimal refresh parameters vary between students.
Memory state
ST experimentally develops a model of each student's memory, i.e. the optimal time window for the ith refresh of a concept. It maintains a model of what the student knows. For all the concepts student has ever learned, ST keeps track of the window for the next refresh. Periodically (every day?) it refreshes concepts for which the current time is in or beyond the window. A refresh can be an assessment. If the score is below a threshold, the student is shown a lesson and assessed again.
It's probably desirable to refresh related concepts together.
The teaching process
Students interact with ST - viewing lessons, doing activities and assessments - through a web browser. This could be a screen-based desktop or laptop computer, a smartphone, or a VR device. It could take place in a physical classroom, or at home, or wherever the student chooses.
The ST interface consists of a static "frame" that provides navigation and control functions. Within this frame lessons are shown.
The student begins an ST "session" by logging in. The student is shown a sequence of lessons. The choice of what lesson to show next is made by an "teaching engine".
The session begins with one or two calibration lessons to estimate the student's mental state, possibly followed by a "stimulator lesson" to improve their state. The session is then an alternation of new learning, memory refresh, and breaks.
The lesson scheduling for new learning is driven by the student's goals and the associated resource shares. The teaching engine computes a sequence of concepts C1...Cn that will cover the goals, and for which the student has all the prerequisites for each Ci. If the student has multiple goals, the teaching engine balances the lessons according to resource shares.
For each concept C, the engine picks a lesson L that teaches C. If there are lessons that currently lack data, the engine may use one of these; otherwise it uses the one whose predicted effectiveness for S is greatest.
If a lesson L doesn't include assessment, the engine shows an assessment that covers L's concept (and maybe others) soon thereafter.
The engine will stick with a topic (a chain of concepts linked by prerequisite) for a while (an hour or so, depending on the student). It switches topics every so often, perhaps after breaks.
As it shows lessons, the engine records the interaction results in the database. If a lesson include assessment, it calls the server-side "grading function" and shows the students the results.
Usually, the teaching engine works in "autopilot" mode: it decides what to show the student, based on goals and memory model. However, the student can select other modes:
- Browsing: the student picks concepts and lessons, following "related" links. If the student find something that interests them, they can add it to their goals.
- The student browses the concept graph, and can see explicit list of lessons for a concept.
- Self-direction: show the student all the concepts on the "could study" list and let them choose.
There are various ways in which an ST system could possibly get students to learn more or faster, or make it more fun. These includes "incentive systems" - giving them badges or some other rewards - and "gameification" - competitive systems where they try to learn more or faster than real (or virtual) competing students.
Tutors
When viewing a lesson, the student can
- indicate things they don't understand
- ask specific questions
Authoring
"ST Authors" are people who create and refine lessons. They are responsible for fixing weaknesses/errors/problems in current lessons and assessments, and developing new lessons.
ST gives authors tools for making better lessons. For each lesson, the author is shown the distribution of predicted effectivness over all qualified students. Some lessons may have high predicted effectiveness but only for a few students; that may be OK. If a lesson is ineffective for everyone, the author can refine or remove it.
Experimentation and student arrival
ST is a framework for automated educational experimentation: it constantly collects and analyzes data about lessons and students, figuring out what lessons are likely to be most effective for each student. Authors are key to this process. When an author develops a new lesson, they let it run until there is statistically significant data. They then look at the data and the student feedback, and possibly refine the lesson.
For this purpose it's best if there's a large, continuous stream of new students. That way, when there's a new lesson, ST can immediately show it to students who are new to its concepts. Once a statistically significant numbers of interactions have taken place, the system will have information about the lesson's effectiveness, and the author will have a basis for possibly improving the lesson.
ST works less well if students arrive in batches and proceed in lockstep, as in the semester model in formal education. In this context an experiment can take months.
The author interface consists of a "dashboard" listing the lessons the author should take a look at:
- new lessons for which statistically significant data is now available
- lessons that had questions or "I don't understand" responses.
Organization and economics
For ST to exist, some money questions must be addressed:
- Who pays authors?
- Who pays to develop ST software?
- Who pays for the servers?
- Do students pay to learn?
- Who manages the concept graph?
- Who vets lessons?
Ideally, I think there should be a single global ST system, run by a "Scientific Teaching Foundation" (STF). The STF develops, maintains, and refines the (open-source) ST software. It operates servers and databases. It vets lessons, and manages intellectual property issues (lessons may be under various licenses, not necessarily Create Commons type licenses).
STF manages the concept graph. Since this requires expertise in all areas, it must be done in a wikipedia-type model where anyone can edit the graph, but all edits are reviewed and vetted by a hierarchy of expert volunteers.
The charter of the STF - managing the world's knowledge and teaching - it vast and central to society. It is therefore subject to corruption by commercial and ideological influences. The internal structure of the STF must be resistant to such corruption. It should be a "scientific meritocracy": the actions and policies of the STF should themselves be determined by data and experimentation. See my essay on Scientific government for some on ideas on what this might look like.
The STF would collect money from various "partners" who use ST (see below). It would use this money to fund itself and to pay authors.
In this scheme, anybody can author lessons. The STF pays authors based on the number (or time) their lessons are viewed. This effectively incentivizes people to develop effective lessons (because those will be selected by the teaching engine) in areas for which there is student demand. It also incentivizes authors to "fill in the gaps" in the concept graph; if there's only one lesson for a concept, it will get shown.
Partners
ST could be used by several types of "partners":
- Schools/universities (public or private) could use ST as part of larger teaching systems, which might include things that ST doesn't have, like in-person meetings, hands-on labs, tutors, etc.
- Companies could use ST to teach and train their employees with content that's specific to the company.
Partners would be able to define their own (proprietary, private) concept graphs and lesson libraries that would connect to the corresponding ST components.
Partners would use the ST teaching engine, possibly with their own framing interface. A corporate training course could restrict the student to the course's concepts.
Partners would have access to some ST information about their students: their memory state for their private concepts, and the view history for their lessons. Possibly other info, though privacy issues would come into play.
Partners would support the STF. They'd pay based, perhaps on the number of teaching engine decisions and the number of ST lesson views.